Could cosmic memory explain dark matter, dark energy, and black holes?
A new theory suggests the universe is constantly recording its own history in the fabric of spacetime. If correct, this cosmic memory could help solve some of the biggest puzzles in physics, from black holes to dark matter and the universe’s ultimate fate.
 Research
Research
NASA's Perseverance rover just ran a marathon on Mars. Could you do the same?
Percy has now traveled more than 26.2 miles on the Red Planet! Could you?
AI image firm Midjourney spins up health division, unveils ‘Ultrasonic CT’
A blog post from the AI image company announced the launch of a whole-body ultrasound scanner users would step into through a pool of water. “We’re building a bold new kind of machine to reimagine the foundations of healthcare and our relationships to our bodies,” the company noted. The “Ultrasonic
 Research
Research
One of these twin stars has likely been snacking on exoplanets
Astronomers have discovered chemical differences between binary stars that indicate one has devoured at least one planet.
 Research
Research
James Webb Space Telescope discovers extreme exoplanet being roasted by its home star
Who ordered the roasted exoplanet? Astronomers using the James Webb Space Telescope found a world that really puts the "hot" in "Hot Jupiter."
 Research
Research
IEEE’s 2026 Education Week Events Emphasized Lifelong Learning
The rapid evolution of the global engineering landscape requires continuous education. For one week in April, the IEEE community focuses on its educational frameworks. IEEE Education Week, which just concluded its fifth year, provided a comprehensive overview of the resources available to profession
 Research
Research
Warframe's latest update is all about space combat, constellations, and cosmic mythology
With its latest major update, Digital Extremes makes space for old mechanics and new ideas in the cosmos.
 Research
Research
Behind the Scenes of a Technical Interview
This article is crossposted from IEEE Spectrum’s careers newsletter. Sign up now to get insider tips, expert advice, and practical strategies, written in partnership with tech career development company Parsity and delivered to your inbox for free!I’ve sat on both sides of the interview table severa
 Research
Research
The 10 best sci-fi TV shows of the 2000s
From 'Battlestar Galactica' and 'Lost,' to 'Fringe' and 'Invader Zim,' this all-star roster of sci-fi programming will have you revisiting all these sensational series.
How the return of the spoils system could reshape U.S. federal science
The Trump administration has reclassified approximately 8,000 senior-level career officials across 54 agencies to Schedule Policy/Career, formerly Schedule F, status. The move strips the employees of standard civil service job protections, making it easier to remove them from their positions. Approx
SpaceX is now worth nearly as much as 41 aerospace peers combined. Its revenue is another story
Days after going public, SpaceX has reached a market capitalization of about $2.5 trillion, even with its stock skidding in midday trading on June 17. At the time of writing, SpaceX CEO Elon Musk was worth more than the next four billionaires on Earth combined. SpaceX laid out its vision weeks ago i
 Research
Research
How Musicians Can Get Paid for Training AI
Musicians are accustomed to getting paid each time their creative work is used. Across vinyl/CD sales, streams, radio, cover versions, and those numerous niches like karaoke, there are agreements in place about what “use” means. Underlying this is a simple economic principle: The more something is u
 Research
Research
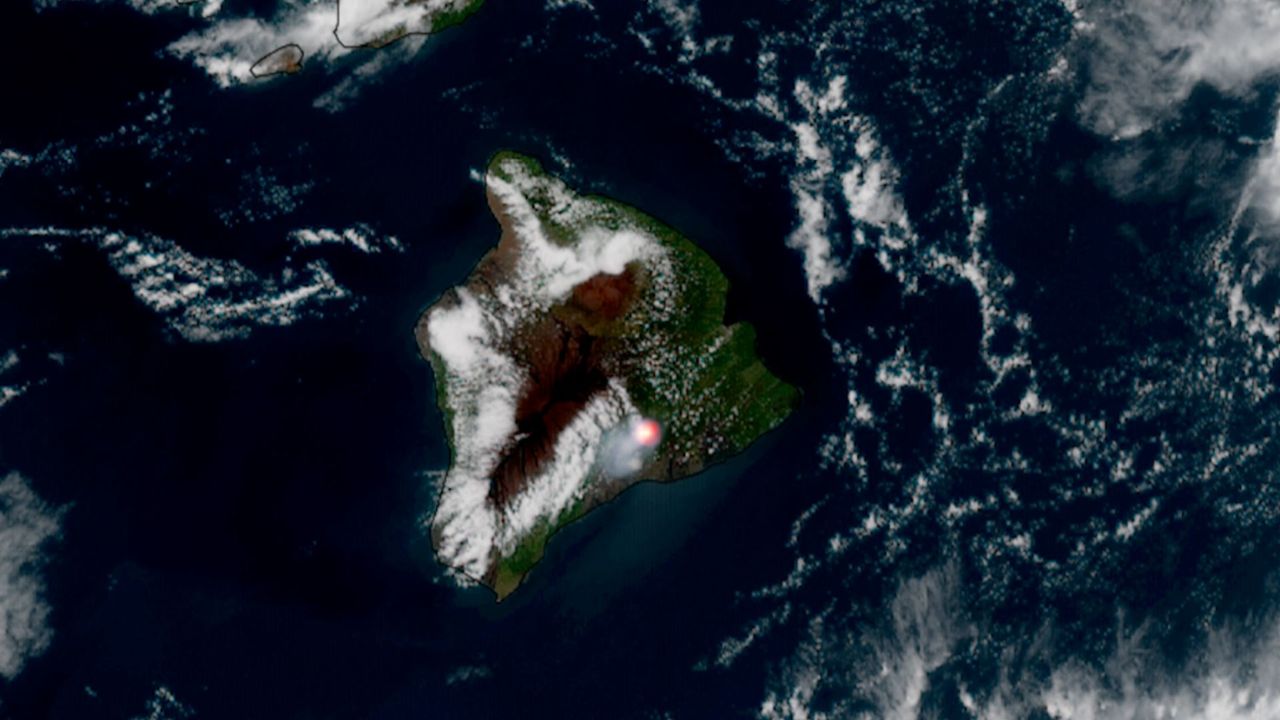
A volcanic eruption seen from space | Space photo of the day for June 17, 2026
Hawaii's Kīlauea volcano shot out lava for the 49th time that we know of.
 Research
Research
The Secret to Marathon-Winning Humanoid Robots
On April 19, 2026, the Honor Lightning humanoid robot ran a half-marathon in 50 minutes and 26 seconds, beating the human world record by 7 minutes and the best robot time from 2025 by almost two hours.How did they do it? Is there some magical technology or technique that unlocked this performance?
 Research
Research
Was life delivered to Earth by asteroids with a helping hand from Jupiter?
Earth may have gotten some of the key ingredients for life from asteroids in the inner solar system, but not without assistance from Jupiter.
 Research
Research
'Best. Mars. Mission. Ever.' Scientists hail MAVEN's legacy as NASA retires Red Planet orbiter
NASA's MAVEN Mars mission ended after 11 years, having revealed how the planet lost its atmosphere and served as a key communications relay for surface missions.
 Research
Research
Stream Season 3 of Silo in safety, anywhere, with 70% off 24 months of ProtonVPN Plus
Can't wait for Season 3 of Silo? Watch this post-apocalyptic smash wherever you are and stay safe online with this superb ProtonVPN deal.
Superconductivity breakthrough could unlock ultra-efficient electronics
A clever nanoscale redesign may have solved one of superconductivity’s biggest problems. Researchers in Sweden discovered that by subtly sculpting the surface beneath an ultrathin superconducting material, they could make it stay superconducting at higher temperatures and under much stronger magneti
New plasma trick could unlock smaller, more powerful computer chips
A new technique could solve one of the biggest challenges in making future computer chips from ultrathin materials. Researchers found that coating molybdenum disulfide with oxygen or fluorine lets manufacturers remove just the top layer of atoms much more safely during plasma processing. The result
 Research
Research
NASA discussing bold mission to boost Swift space telescope today: Listen live
NASA will discuss an ambitious mission to boost the orbit of its Swift space telescope during a press conference today (June 17), and you can listen to it live.